In this series of blog posts we will take a look at some of the key technical challenges that arise when building a core banking system in a distributed environment. In this, the first post in the series, we lay the contextual groundwork by exploring some key characteristics of the earlier generations of core banking systems. We continue by examining a third wave of banking systems that emerged around the turn of the century which attempted to solve the problems the banks were having, and analyse why they struggled to take hold. We round off the exploration by introducing some key system characteristics that would be required to enable the banks, many of which are still running mainframe systems developed in the 1970’s, to migrate from their burning platforms to a new generation of systems.
We start by taking a quick look at what are the key capabilities of a core banking system, often referred to simply as ‘the core’, or system of record:

- Ledger: the heart of the core, this is the immutable list of the transactions that have been processed by the core, often regarded as the source of truth for movement of funds in the bank
- Accounts: the core account record that might map to a customer account but equally could map to a bank owned account or a special accounting record such as a nostro or wash account. Each transaction in the ledger references both a debit and a credit account
- Balances: the core computes balances across all of it’s accounts. Depending on the complexity of the core, this can range from a simple balance for each account, to a more involved structure that tracks multiple dimensions within each account, such as asset, currency and ring-fenced funds
- Product engine: a broad term to encapsulate any ‘product’ decisioning the core might make around an account. The simplest case is deciding if any given transaction is allowed to be added to the ledger, which would typically involve a balance check. The scope of the product engine differs from core to core and can involve anything from interest calculations to sweeping funds across accounts to meet complex processing rules.
The terminology is often overloaded, but generally speaking when banks talk about the ‘core’ they are concerned with these key central capabilities, and when they refer to a ‘core banking system’ they may be more broadly referring to a wider stack that could include additional capabilities. Commercial off the shelf ‘bank in a box’ / ‘black box’ core banking propositions often include more of this wider stack, and replacing such systems now sit at the hearts of the IT challenges of many banks.
An emerging new generation of core banking systems
When we look at the evolution of core banking systems over time we see a somewhat unsurprising trend: banking systems seem to slowly but surely follow emerging patterns in software architecture. Given that many banking systems available on the market today are still comprised of monolithic, batch based style architectures, it is only a matter of time until a new generation of systems take hold that embrace the increasingly established practice of cloud based microservice architectures, broadly synonymous with a distributed environment.
To understand the pace at which banking transformation lags behind other industries it helps to look at where it began. The ‘first generation’ of cores that emerged in and around the 1970’s were built to emulate a model of banking that has been in place for hundreds of years - which makes sense, if it works, why change it?
This model typically involves a series of branches, that close at 5pm, at which point end of day positions are calculated and collected in a centralized ‘general ledger’, which acts as the centralised repository for accounting data in the bank. When the first generation systems emerged there was a key requirement to have a unified network enabling customers to transact in any branch. Since this was before the dawn of a stable public internet, server communication was slow and unreliable. Systems would typically connect using a client-server model, and would use two phase commit protocols to guarantee message delivery, which further increased the cost of communication. To work around this problem banks would typically place all of their key systems and data on a single machine. The result was these earlier core banking systems were monolithic in style, and were exclusively designed to run on expensive mainframes, which were the only machines capable of handling the number of client-server sessions required to service all branches belonging to a given bank.
As we moved into the 1980’s consumer banking evolved to be less branch centric, the first generation systems were extended to support emerging channels such as ATM’s and call centres. This spurred on a second generation of system’s that could handle these newer channels and increased demand for server capacity, however the underlying architecture remained largely unchanged.
Banks invested a huge amount into these earlier systems which meant they were incredibly resilient, and could handle a huge amount of throughput at low latencies, even by today’s standards. The fact that many banks today still run these systems is testament to their success. This being said there is an important trade-off in that these systems are incredibly expensive to run, especially given that they have to be sized for peak processing, which is typically end of month reconciliation, leaving expensive capacity idle for large periods of time.
Whereas these earlier systems were considered successful for a long time, we are seeing banks increasingly shift focus towards core transformation, which hints to the fact that many of these banks are running on ‘burning platforms’. The typical first generation core was written to satisfy banking products from the 70’s, the needs of the regulator and consumer demands have shifted significantly since then, and continue to shift. A 2019 report by CACI estimated 25 million UK customers use mobile banking applications, this social trend alone has driven the need for continuous change and the need to handle the more volatile and 24/7 nature of mobile banking needs. Unfortunately for banks still encumbered with mainframes, not only are they expensive to run, the cost of change is also high. Compounding this problem, banks are facing increasing pressure to reduce cost.
The third generation
Reacting to these pain points, as we approached the turn of the century we began to see a new generation of core banking systems emerge, sometimes referred to as the ‘third generation’. These systems addressed many of the issues that the banks were experiencing. They had parameterizable product engines, making change cheaper and less risky. Riding the wave of the advent of web/online banking, these systems would often come with rich UI capabilities, however since they were often tightly coupled to their respective UIs it could be difficult to compose this new found flexibility in novel ways.
They were generally written in more modern programming languages and deployable into application servers which paved the way for the banks to ditch their expensive mainframes, however, these applications were generally stateful, and relied on session management, making it difficult to scale in any way other than vertically.
Whereas this new wave of core banking systems addressed a number of the challenges banks were having, some key pain points remained. These systems still largely use batch based processing and are monolithic in style, and since they were no longer tied to the expensive yet effective mainframe, they can actually be observed to be less resilient and performant when compared against their predecessors. This could explain why the third generation struggled to take hold, whereas there has been traction up to the tier-2 banks, they have failed to penetrate the tier-1 market in a meaningful way.
This caused a problem for the larger banks as they struggled to progress their core transformation projects. Banks that didn’t want to risk moving away from their mainframes instead found inventive ways to work around the problem of the legacy core:
- ‘Hollow out the core’ is rapidly becoming the de facto strategy, and involves pulling the product engine, along with other key capabilities, out of the core. The result is banks can rely on more modern products to solve some of the shortcomings of the legacy core, however the downside is that there is an increased operational complexity and integration challenge. Additionally, the proliferation of these tactical systems causes data silos which lead to additional overheads such as data mastery concerns as well as data provenance, reconciliation and attestation concerns
- Deploy API ‘shims’ onto the mainframe. Some banks have gone down the route of installing software directly onto the mainframe that can expose previously difficult to extract data via modern APIs. The advent of PSD2 and open banking led to a number of high profile implementations of such an approach, however there is a dangerous trade-off in that since the underlying systems lack the elastical scaling properties to handle the resulting volatile workload volumes, banks could inadvertently trigger a DDoS attack on their on core systems
The result is that the larger banks have been able to survive by modernizing the stack around a legacy core. Whereas this may work for some time, we have only delayed the inevitable: there is only so long a bank can survive with a dying core. The more that is pulled out of the core the more we bleed complexity into the mid-tier which causes data silos, and increases overall system fragility.
The cracks began to show in the wake of the global financial crisis as the banks were faced with a difficult challenge in that they had to both drive the costs of their IT infrastructure down to allow them to maintain competitive banking products in the market, as well as having to adapt to shifting consumer expectations and increasingly stringent regulator demands. A notable example of the latter being the introduction of the third installation of the Basel accord, Basel III, which places increasing demands on banks to adapt their core systems in ways that seem to directly clash with the traditional model of end of day batch style processing, such as the requirement of intraday liquidity management.
All of a sudden the banks found themselves facing two key challenges that seemed to conflict with each other. To drive the cost of their infrastructure down they needed to get rid of their mainframes and run on leaner infrastructure which would lower the glass ceiling on the amount of processing power in the system. At the same time, to adapt to regulatory changes they had to increase the frequency of their batch processing jobs, which would require more processing power.
Compounding the problem, core banking systems are often designed in such a way that they can only run when the core ledger is closed. There are a number of reasons this makes sense, such as to avoid resource contention between batch processing and online traffic, as well to ensure transformations are run on a stable (static) data set. Given that our traditional model of banking was only open for business 9am - 5pm, shutting the core made perfect sense for early generation systems. As consumer demand changes, and 24/7 banking became the norm, third generation systems generally adapted by shortening the time the core was shut for, and by giving the ability for the system to run in ‘stand-in’ mode so that payments are buffered as the bank transitions over the end of day process. This comes with its own complications as we add considerable complexity into the system, we find ourselves building a bank within a bank to handle stand-in and having to jump through hoops to fold in the stand-in ledger at the start of the next banking day. The net result is running the same batch based operations throughout the banking day is often not feasible.
To summarize our exploration into the challenges the banks face with their incumbent core’s, we draw focus to one common limitation - given that they are all inherently monolith in nature, they can only be scaled by one dimension - vertically. This fundamentally inhibits the banks’ agility, both in terms of adapting to change, and their ability to reduce cost.
Fortunately for the banks, there is hope. We are dealing with a common problem that exists in many domains both within and outside of financial services, a problem that begins to be addressed with a microservice based architecture. In such an architecture each part of the system can dynamically scale in and out, enabling the application to elastically adapt to whatever processing needs you can throw at it whilst keeping non affected parts of the system scaled down, ensuring the overall footprint (and as a result cost) of the system remains low. As a result a microservices based architecture paves the way for a scalable, and real time focused core banking system.
So, why do the third generation cores simply not refactor their existing systems, splitting up the monolith into a microservices based architecture?
Carving up the core banking monolith
To answer this question it helps to look at some of the key benefits of monolithic architecture. A monolith has a single physical clock, and therefore easy access to a single global (total) ordering. Having a total ordering makes ensuring correctness in any given request relatively straight forward. As the monolith is split up, we lose the common clock, and as result, the ordering. This means correctness becomes difficult to uphold. Application logic may have to be considerably refactored to handle race conditions and bottlenecks caused by network latency. It can often be the case that without totally refactoring the system from the ground up, ensuring causally related events are processed in the right order without significantly sacrificing system throughput can become an intractable problem. In addition to this it can be easy to fall into the trap of simply creating a ‘distributed monolith’, and as a result being burdened from the worst attributes of both paradigms.
On the cloud vs. cloud first
As the third generation systems struggled to carve up their monoliths, and facing increasing pressure from the market to ‘move to the cloud’, vendors often employ a lift and shift strategy taking their monolithic app server, containerizing it and deploying it on the cloud. Whereas this technically qualifies as a cloud strategy we could argue it isn’t a very effective one, we haven’t leveraged any of the benefits of being on the cloud, notably, elastic scalability - we are essentially dealing with the same monolith, but now in a more expensive data centre!
Building on this it might seem that conditions are ripe for a new wave, a fourth generation of core banking systems that are built from ground up embracing the elastic scalability of the cloud by leveraging a microservice based architecture.
Why hasn’t this already happened?
There are a number of reasons that could explain why we’re only just beginning to see a new generation of core banking systems emerge:
- Banks generally move slow. They have a historically cautious nature, which is understandable given the criticality of the data they are managing. There is typically a lot of governance around IT change in order to mitigate risk, with the unintentional side effect of slowing things down
- An effective development ecosystem and culture can take years to organically grow, which means banks find themselves with a dilemma, as key skills like Cobol are disappearing from the marketplace, and transplanting a new in house team focused on a more modern development ecosystem can be a long term endeavour
- Up till recently the cloud generally wasn’t trusted by regulators, inhibiting banks from leveraging cloud infrastructure to lower the entry barrier to scalable infrastructure
However we argue that a key reason is simply that building a bank in a distributed environment is hard.
When we are dealing with a microservices based architecture we are inherently dealing with a distributed environment. This means we are dealing with a system that has to work with broad range of latencies: any given journey through the system will likely spend most of its time on the network between services, as Gregg (2013) illustrates, if one CPU cycle were to take one second, a network hop from SF to NYC would take 4 years. It also means we are at the mercy of the ‘fallacies of distributed computing’. On top of not having a common clock as we previously explored, we are facing an unreliable network in which requests can be delayed indefinitely or lost completely.
In many other industries we might be ok with losing the odd message, or dealing with the occasional race condition, however in banking correctness is the number one priority. We cannot lose a single message as this could result in anything from a customer's balance falling out of sync, to large sums of money evaporating into the ether.
Since ensuring correctness in a distributed system is a hard problem, building a microservice based core banking system is a challenge.
So what does the ‘fourth generation’ of core banking systems look like?
The next generation of core banking systems must be built using a cloud first approach in mind. Elastic scalability must be baked in. Mechanisms to ensure correctness must be baked in. Hyper flexible configurability must be baked in. These systems must both be able to scale out to handle massive throughput, and scale in to run on a minimal footprint in periods of low activity. These systems must be real time, there must be zero data loss, and zero planned downtime, and critically: never shut the core.
The ‘headless core’
Building on this it is important that the next generation of banking systems should be conservatively scoped. The mainframe systems suffer from having their core ‘hollowed out’ making them too dumb. The third generation systems suffer from being too tightly coupled to their interfaces making them a black box, and a result, difficult to change. An emerging term banks are using to describe their transformation needs is the ‘headless core’.
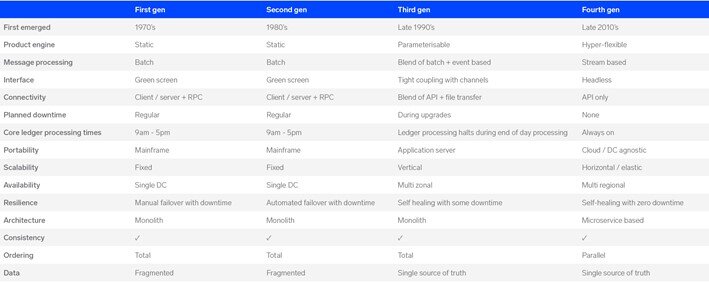
To help visualize what a fourth generation system should look like we take a look at some typical capabilities of the previous generation systems:
So why now?
Cloud and Microservice architecture was up until recently ‘cutting edge’. This is rapidly changing as the cutting edge becomes mature, accepted practice. Cloud vendors are now working closely with regulators, and they are also doubling down on their infrastructure as the networks become faster and more reliable. Many banks have already deployed production systems into cloud environments. Organisations that dominate the mainframe space are waking up to this, with IBM’s recent announcement of the launch of the ‘worlds first financial services-ready public cloud’. Tooling and frameworks are emerging that bring the once theoretical side of distributed computing into common practice, such as Kubernetes, Istio and Kafka. Building on this, the growing popularity of NewSQL databases such as Google Spanner and CockroachDB, which generally use quorum based consistency so that writes can be directed to any node, means that now the database can scale with the application, paving the way for true linear scalability. The cumulative result is that we are undoubtedly at the inflection point of the emerging fourth generation of core banking systems that targets the needs from the smallest of community banks to the largest of global tier-1 banks.
Vault Core - a fourth generation core banking platform
At Thought Machine, when we embarked on our journey of creating Vault Core, we both saw the challenge and recognized the opportunity. We carefully designed a system from the ground up that was able to operate efficiently in a distributed environment without sacrificing correctness or ever shutting the core. To achieve this we understood that it was critical that we both started as and remained an engineering and product focused organisation.
We designed Vault Core to handle high throughput within reasonable latencies, whilst ensuring zero data loss. Finding the right balance between system characteristics is key, as any distributed systems engineer will tell you - it’s a game of trade-offs. Every design decision trades off a number of key system attributes including throughput, latency, availability and durability - the laws of physics tell us we cannot have it all. Vault carefully chooses the right trade-offs in the right places.
This concludes the first post in this series. Following from this we will focus on a number of technical deep dives into some of the architectural patterns we used to build Vault Core. We will explore how the system as a whole can be seen as ‘holistically consistent’, as we lean on eventual consistency where we can, and when it is needed we ensure strong consistency is on hand. We will explore how we enable the system to scale by leaning on established patterns such as shared nothing architecture, asynchronous / event-based processing and selective backpressure. We will explore how correctness is upheld by using approaches such as at least once delivery with idempotency, resource bitemporality and optimistic locking. In the next blog post in this series we will dive into how we utilize vector clocks and optimistic locking to scale our core transaction processing pipeline.
———
Learn more about Vault Core now.
References:
The growth of digital banking report, CACI: https://pages.caci.co.uk/rs/752-EBZ-498/images/caci-future-growth-digital-banking-report-2019.pdf
Gregg, Brendan. 2013: Systems performance: enterprise and the cloud
IBM financial services cloud: https://newsroom.ibm.com/2019-11-06-IBM-Developing-Worlds-First-Financial-Services-Ready-Public-Cloud-Bank-of-America-Joins-as-First-Collaborator